

5·
11 hours agoEven with the comment making a lot of sense, if someone has a good summary / write up / video that helps build an intuition or understanding a bit more of thermodynamics then I’d love the recommendation

Even with the comment making a lot of sense, if someone has a good summary / write up / video that helps build an intuition or understanding a bit more of thermodynamics then I’d love the recommendation

Two ignorant questions for you:
Do you see any benefits to teflon over carbon steel?
I’ve been using airbnb a bit and sometimes the tops are some form of electric (but I’m ignorant enough not to know what type of electric) and by far the most brittle part seems to be the touch buttons that many have. Do you have any pointers on shopping around for stovetops without issues with the buttons?

please don’t drag me into “bias people” conversation
This whole part is very confusing, and I think you a misreading “you’re going to bias”. Like priming. Say “look at the quality of this” to certain people and they’re far more likely to say it’s beautiful even if they know nothing about it. In this case, being ignorant but trusting can be harmful. Agreed there are some that have no lookalikes. I think we disagree about how much you can trust different sources and how important it is to make that point vs keep beginners overly cautious
Thanks! Sorry for spreading the FUD
Probably answered below:
All will work with induction, except for cheap aluminum nonstick pans
I thought it was more involved than that but after a quick search online I’m wrong
Induction also requires specific pans, right? So a regular cast iron pot won’t work?
I’m pretty ignorant here but my time on iNaturalist disagrees. I also think that if you’re going to bias people one way or another then biasing them to know the look a-likes is important, and promoting being cavalier is a bit reckless
I don’t think there is a federal law, just some state laws and you can complicate those by using federal officers. This is the best summary I’ve seen:
Ahaha. The morning after I’m drunk I wake up to people pointing out I was harsh, blunt and wrong
I upvote if I want to promote the behaviour and downvote for the opposite. When I downvote I try to leave a comment saying why, if I think they’ll read it and be interested. Sometimes those comments are very unpopular and I get a chance to reevaluate my position.
For shared information like links (which are most of the posts I see for the communities I’m in) I upvote if I think it is important for people to see or interesting and downvote if I think there is important context missing, it’s misleading (or sometimes if the source is) or is someone spamming.
For commentary (so some posts) I upvote / downvote based on how much I agree. If I have something to add I’ll add it but if I don’t then “me too” isn’t a meaningful interaction to me.
Mixed links with commentary annoy me a bit since you can usually spit them. And same for long posts. But, I’m not going to downvote or anything, I’ll just avoid the interaction unless some part of it is exceptional.
A peeve of mine is when it seems like people are downvoting links / posts when it seems like the downvotes are because people disagree but also seem to think it’s important to be aware of. Say, a recent Trump action. Obviously it’s hard to guess intent but votes for subcomments can make it seem like a lot of people do this sometimes. But… a vote without an explanation leads to reading tea leaves
I wouldn’t even say clueless, he’s from Brasil. Name some Candomblé holidays and how they attend. Most tourists don’t know the religious holidays or the practices of the places they’re visiting. The synagogue isn’t saying it was based in bigotry.
That said, a visiting law professor breaking car windows with a BB gun raises enough eyebrows on its own.
Your profile description is “I am the one who FUCKS FUCKS FUCKS Your wife!”?
I think the first part you wrote is a bit hard to parse but I think this is related:
I think the problematic part of most genAI use cases is validation at the end. If you’re doing something that has a large amount of exploration but a small amount of validation, like this, then it’s useful.
A friend was using it to learn the linux command line, that can be framed as having a single command at the end that you copy, paste and validate. That isn’t perfect because the explanation could still be off and it wouldn’t be validated but I think it’s still a better use case than most.
If you’re asking for the grand unifying theory of gravity then:
It’s an NBC news poll so I’m not sure it’s easy to find much more info on the poll or its history.
Here’s a chart showing previous responses:

Yeah, for me some of it is that I got more nuanced and forgot the places I used to be black and white / aim for a harsh burn. Not that I’m not still ignorant with plenty of black and what thinking.
And I think that besides people chasing upvotes, there is also more organising of movements online and by pushing issues into ethical framings that demonise the other side you create anger that keeps a movement going and can be directed but then large groups lose the ability to talk with nuance about that topic
Is it?
I think this is more confounded than “average” and I think that even in their turning point analysis they’re being excessively specific:
Yeah, agreed. It reads as if a bunch of computer scientists did some data analysis without statisticians or biologists.
Here’s the original paper:
https://www.nature.com/articles/s41467-025-65974-8
They’ve taken a number of measured attributes:
All graph theory metrics were calculated using the Brain Connectivity Toolbox (BCT) in MATLAB 2020b38. Global measures included network density, modularity, global efficiency, characteristic path length, core/periphery structure, small-worldness, k-core, and s-core, while local measures utilized were degree, strength, local efficiency, clustering coefficient, betweenness centrality, and subgraph centrality.
Smoothed to fit a curve to the data:
In these models, cubic regression splines were used to smooth across age, and sex, atlas, and dataset were controlled for.
Reduced the dimensions using Uniform Manifold Approximation and Projection. Basically, if you have this data “height in inches”, “height in cm”, “weight in kg” it would ideally keep “weight” roughly the same but have a single “height” but you couldn’t rely on the units. They condense the input data down to four dimensions keeping age as the independent variable.
To project topological data into a manifold space, we used the UMAP package in Python version 3.7.335. Before data was put into the UMAP, it was first standardized using Sklearn’s StandardScalar
Then they created a polynomial fit for each dimension:
Polynomials were fit using the polyfit() function from the numpy package, which uses least squares error95. Together, these polynomials create the 3D line of best fit through the manifold space. For our main analysis, we fit 5-degree polynomials
Then they found the turning points and where they were are the ages. Here’s a plot and you can see even after all this cleanup the ages are noisy and it’s really surprising they’ve chosen ages as specific as they have:
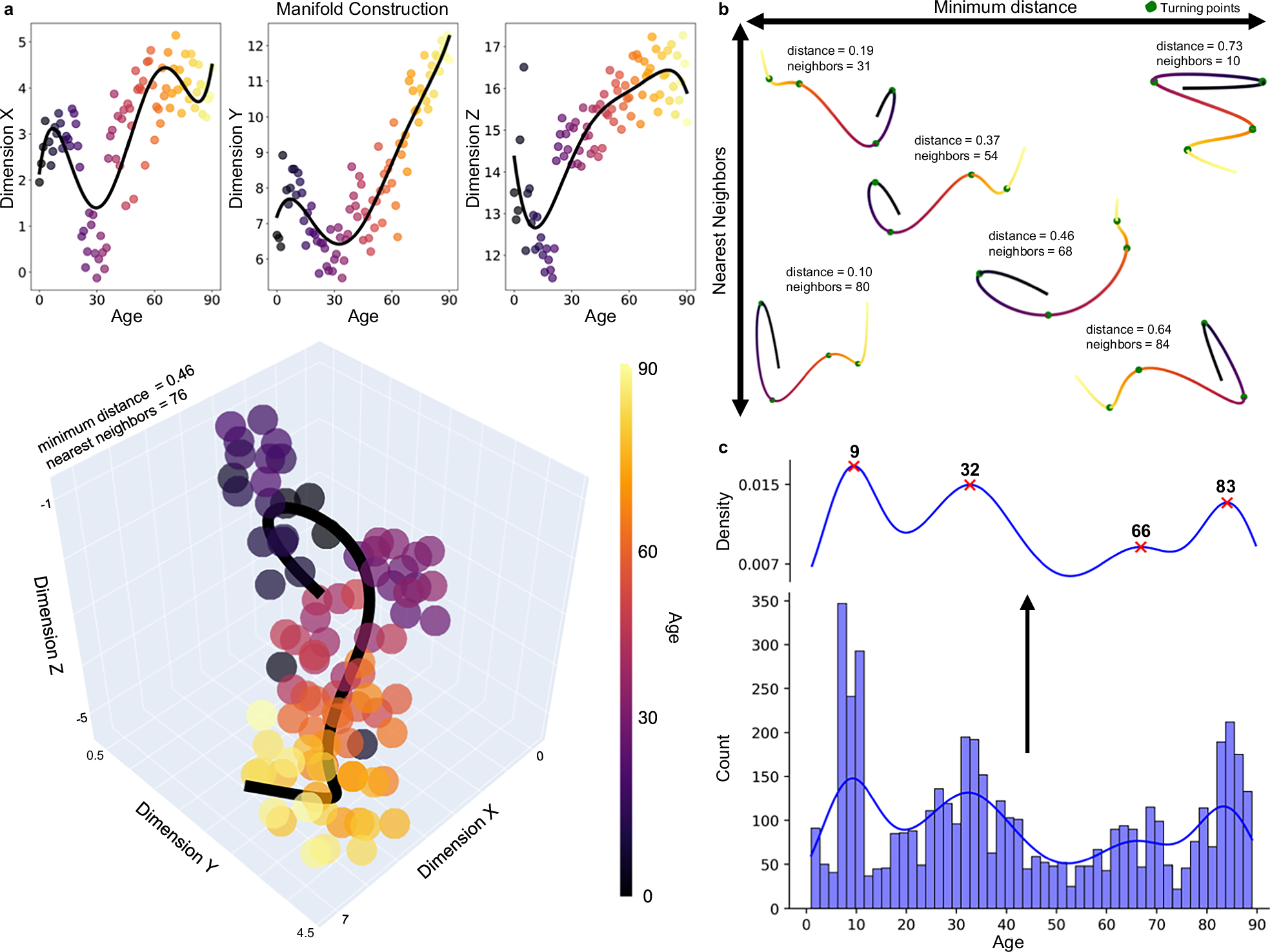
I have no idea how they went back through to make up the summary for each “epoch” they identified. There’s obviously a lot of information for them to use here but it also seems like there could have been more creative license than ideal.
It really reads as an early idea that I don’t think should be pushed to the general public until other scientists have scrutinised it more (otherwise you end up with a whole lot of coffee is dangerous, coffee is healthy leading to people not trusting science)
Fuck the YouTube PMs
They were condescending on the bug with the fourth highest internal ratings that simply requested that shorts could be removed (particularly for children and for mental health). A particular gripe of some engineers was that it couldn’t be removed from the subscriptions page. I was impressed they removed the condescending comment after a month but they never really addressed the large volume of employees telling them this was the wrong thing to be doing

Thanks the taking the time. I always find it hard to follow up and point out the ambiguity / alternative without coming across in some unwelcome way

{kind=link}
{kind=link}
Why is this being downvoted so heavily?